

Hope you have heard about the Oracle’s Self Driving Autonomous Database. Autonomous Database is an autonomous data management software in the cloud to deliver automated patching, upgrades, and tuning — including performing all routine database maintenance tasks while the system is running — without human intervention. This new autonomous database is self-driving, self-securing, and self-repairing, which helps to eliminate manual database management and human errors. Also, there is also a secret weapon called Machine Learning in a Box built into the Oracle Autonomous Database Platform. Here is a quick lab guide to get you started on how to use the Oracle Autonomous Database Platform.
In this article, I would like to walk you through a practical example of how we can take advantage of the Machine Learning capability in the Oracle Autonomous Database Platform and make decisions instantly.
Here is a background of our Fictitious company: Vision Housing Finance Corp that deals in home loans. They have a presence across all urban, semi-urban and rural areas. Customer first applies for a home loan after that company validates the customer eligibility for a loan.
Problem
VisionCorp wants to automate the loan eligibility process (real-time) based on customer detail provided while filling the online application form. These details are Gender, Marital Status, Education, Number of Dependents, Income, Loan Amount, Credit History and others. So they would like to understand if they can take their existing data sets and apply some machine learning to automate the loan decision-making process. You can download the historical dataset that this company has provided from here.
One of the most prominent features of a machine learning platform is Notebooks. Notebooks provide a web-based collaboration tooling to create and share documents that contain live code, equations, visualisations, and narrative text. It uses include data cleaning and transformation, numerical simulation, statistical modelling, data visualisation, and data analytics. The most popular Notebook tools being Jupyter and Zeppelin.Oracle Machine Learning in Autonomous Database uses Zeppelin Notebook. Based on my research so far Notebooks is targetted towards Data Scientists who understand how to write code in R or Python to weave through heaps of data sets to prepare the models, train the data and arrive at specific predictions.
However, we don’t need data scientists to prepare the learning models or predictions in the Oracle Machine Learning Platform. If you are familiar with SQL or PL/SQL, you can very much use that knowledge and take advantage of the machine learning capabilities and run these processes directly on the data. Autonomous DB takes away the pain of moving the data around (both input data and the predicted data). So let’s see how we can apply machine learning in Autonomous DB in action.
Provision Autonomous Database (ADW or ATP) and Load the Data
Following the lab instructions mentioned Here to provision an Autonomous Database and load the Loan data set into the ADW/ATP platform.
Create a developer user to execute the machine learning steps below. When you create a machine learning user (instructions for the same are mentioned in Lab 4 in the above link), will create an actual Database user. For this exercise, I have created a Table called LOAN_VISIONCORP in my data warehouse and loaded the historical data shared by Vision Corp.
Prepare the Machine Learning Process to identify the pattern in the current data set for Loan Approvals.
Login into the Machine Learning UI with the developer user created in Step 1.
Tip: Make sure you click on Home when you are in the Admin UI that should navigate you to the Developer Interface.
Create a new Notebook and start creating the paragraphs where we can write SQL or PL/SQL to inspect, model and predict based on the data we have loaded. In our case, we would like to understand the current trend in the Loan approval process by learning from the data from existing customers and apply that for future customers.
Step 1: First Let’s query on the Table first that we just loaded which shows existing customers who have either been approved the Loan, or their loan was rejected. In the notebook, you just created, execute the below query in the first paragraph.
select * from ADMIN.LOAN_VISIONCORP

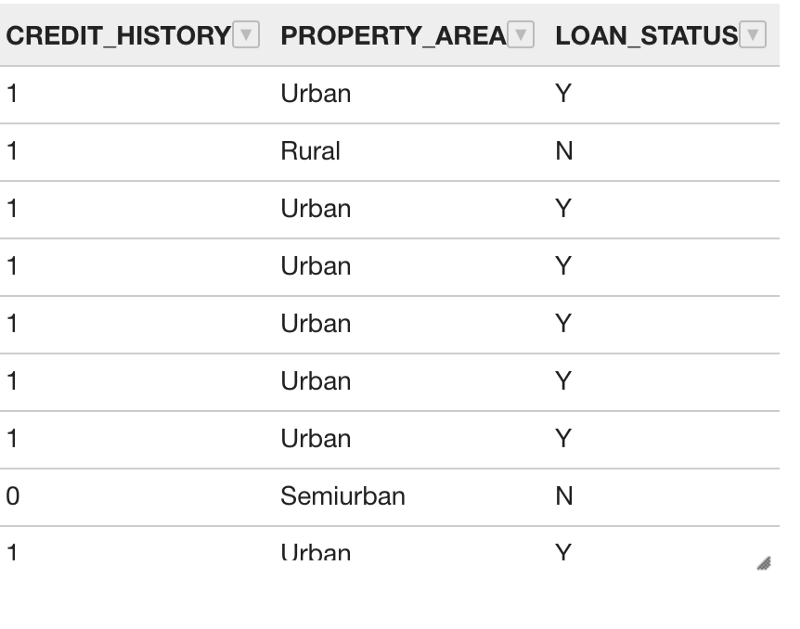
If we look at the above customer data and their Loan Status, it appears like all the attributes like Education, Income, employment etc. contribute to their loan being approved or not. Here is where the secret sauce of Machine Learning comes into play to identify the patterns between these attributes and the Target Attribute (In our Case Loan_Status).
Step 2: Let’s split the data set into two parts, a training data set and test data set. I have applied the 70–30 ratio here. For this exercise, I chose to create two Tables for Training Data and Test Data.
CREATE TABLE VISION_TRAIN_DATA AS SELECT * FROM ADMIN.LOAN_VISIONCORP SAMPLE (70) SEED (1);
CREATE TABLE VISION_TEST_DATA AS SELECT * FROM ADMIN.LOAN_VISIONCORP MINUS SELECT * FROM VISION_TRAIN_DATA


Step 3. Prepare the Data Classification Model with one of the seeded machine learning algorithms. Before we do this we need to create a Table with Hyper Params for our Model. And in this table, we have the only configuration that contains the Type of Machine Learning Algorithm we would like to use on our Data Sets. For this exercise, I went with “ALGO_DECISION_TREE” as we intended to understand the decision making behind the Loan Approval.
%script
BEGIN
EXECUTE IMMEDIATE ‘CREATE TABLE VISIONCORPLOAN_BUILD_SETTINGS (SETTING_NAME VARCHAR2(30), SETTING_VALUE VARCHAR2(4000))’;
EXECUTE IMMEDIATE ‘INSERT INTO VISIONCORPLOAN_BUILD_SETTINGS (SETTING_NAME, SETTING_VALUE) VALUES (‘’ALGO_NAME’’, ‘’ALGO_DECISION_TREE’’)’;
EXECUTE IMMEDIATE ‘CALL DBMS_DATA_MINING.CREATE_MODEL(‘’VISIONCORPLOAN_CLASS_MODEL’’,’’CLASSIFICATION’’,’’VISION_TRAIN_DATA’’,’’LOAN_ID’’,’’LOAN_STATUS’’,’’VISIONCORPLOAN_BUILD_SETTINGS’’)’;
END;

Note: To build and train the Model we need to use one single pl/SQL command DBMS_DATA_MINING.CREATE_MODEL that accepts the params. Provide a model name and the training method to be used (in our case we are using Classification), the data table to be used (training table created earlier) and the Target Variable and the hyper params. This is all required to train the model
Step 4: Test the quality of the model by applying the above model to the Test Data Set (30% dataset we extracted from the master data set). When we test the model against this dataset, we can predict whether the test data set customers are eligible for the Loan or not based on the training we did in the above step.
- Create a new Placeholder column(Prediction) in the Test Data
ALTER TABLE VISION_TEST_DATA ADD LOAN_STATUS_PRED VARCHAR2(20);

- Let’s run the prediction to fill the new column we just added in the Test Data Table.
UPDATE LOAN_TEST_DATA SET LOAN_ELIGIBILITY_PRED1 = PREDICTION(LOAN_CLASS_MODEL USING *);

- Let’s query the Test Data Table that contains the data of all the customers with their Original Loan Status along with the Machine Learning Model Loan Status Prediction applied on the new column.
SELECT LOAN_ID,LOAN_STATUS, LOAN_STATUS_PRED FROM VISION_TEST_DATA;
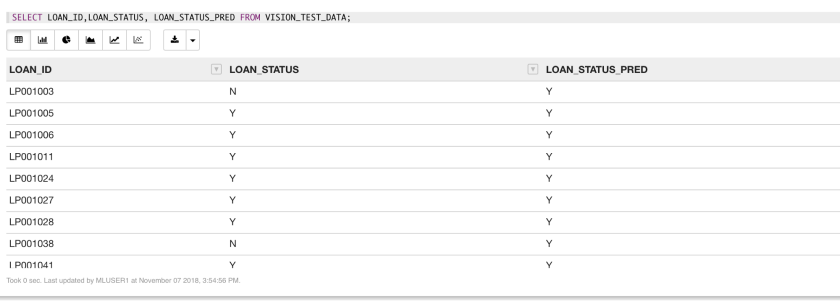
- Let’s understand what percentage of the cases our prediction is accurate.
SELECT TO_CHAR(((SELECT COUNT(*) FROM LOAN_TEST_DATA WHERE LOAN_ELIGIBILITY = LOAN_ELIGIBILITY_PRED1) /(SELECT COUNT(*) FROM LOAN_TEST_DATA))*100,’999.99') CORRECT_PRED_PERCENTAGE FROM DUAL;

- We can go one step further and understand the prediction with the help of confusion matrix, given that we have the Loan Status from the Test Data and the status from the Prediction after applying the Machine learning model and grouping them on these attributes.
SELECT LOAN_STATUS, LOAN_STATUS_PRED, COUNT(*) from VISION_TEST_DATA GROUP BY LOAN_STATUS,LOAN_STATUS_PRED ORDER BY 1,2

We can see here the True Negative count, The false Positive count, false negative and true positive count of the Loan approvals based on our Prediction model.
If we now insert a new customer data into our Test Data or create a new Table and insert the latest data and apply the prediction model we can determine if these customers would be eligible for the Loan or Not. I would be interested to know how that went with you. Looking forward to your inputs. Thank you for your time.
