I’m sure we can all agree, adopting a cloud strategy is awesome. The opportunities and benefits it affords are many. However cloud governance is an ongoing problem that plagues security, compliance, and management teams, which cloud vendors like Oracle are continually trying to solve.
If you’re reading this, you’ve probably been asked, or heard at least once:
Who has access to what in our environment?
Any Security / Compliance Manager
The answer should be easy and simple. However the reality is likely lots of manual time & work, spreadsheets, and endless clicking in a cloud console. If you’re doing this manually then I agree, it’s time that you could be dedicating to more important tasks.
The challenge in trying to answer these questions:
- What users exist and what groups do they belong to?
- What does my OCI tenancy compartment structure look like?
- What policies have users explicitly created?
- What permissions do users have in my tenancy?
- Are there any excessive / non-compliant policies & permissions in my tenancy?
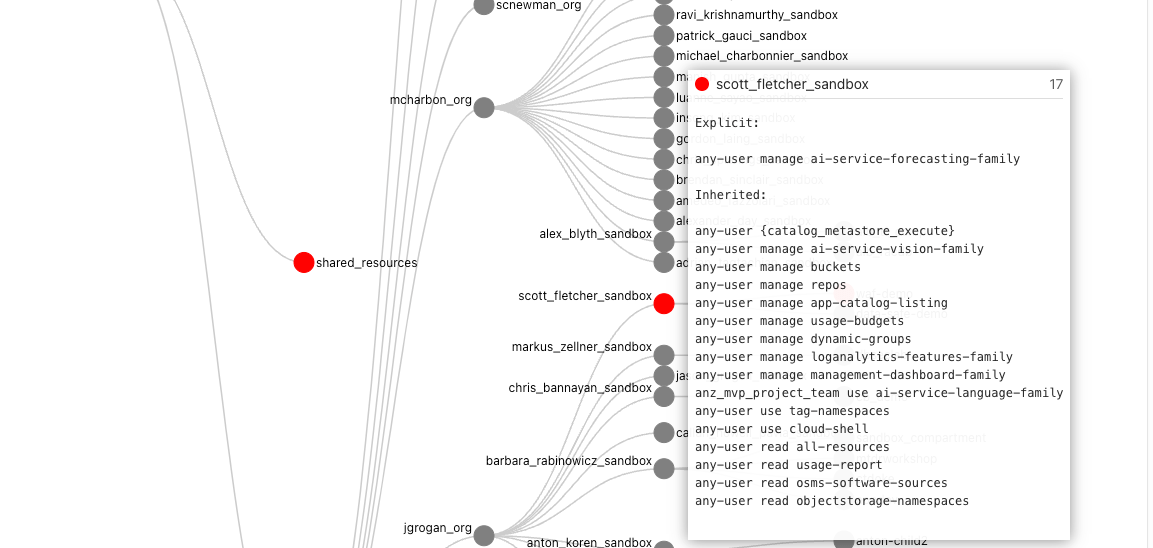
is that these complex relationships can’t be easily represented and interpreted in a table-like format. In the OCI ecosystem:
- users can be federated with an Identity Provider and can belong to one or many federated, or local IAM groups,
- policies can be defined for “any-user” or for a group,
- policies are inherited meaning they apply to all sub-compartments from which the policies are applied.
To make things easier I’ve created a solution using Oracle tools and services to simplify the auditing of OCI tenancies and user permissions called “Peek”.
Note: If you have an OCI tenancy with IAM Domains instead of IDCS, use these instructions https://redthunder.blog/2023/03/20/oci-iam-domains-user-access-review/ instead of those below.
Note: From 22/05/2023 APEX is no longer required as the solution runs entirely inside the container. To run the new container for OCI with IDCS use the following command:
docker run -it --name peek --rm \ --mount type=bind,source=/Full/Path/To/.oci/,target=/root/.oci/,readonly \-e OCI_PROFILE_NAME=<from your OCI config> \-e OCI_TENANCY_OCID=<from text file> \ -e OCI_IAM_URL=<from text file> \ -e IDCS_URL=<from text file> \ -e IDCS_CLIENT_ID=<from text file> \ -e IDCS_SECRET=<from text file> \-e TOOLTIP_LINE_PX=20 \ -p 4567:4567 \scottfletcher/oci-peek
After the docker container has started, you can access the web interface using the locally mapped port http://localhost:4567. You should see a progress window:

Once the mapping process is complete the visualisation will appear.
Depending on how long your policy statements are, you may wish to adjust TOOLTIP_LINE_PX to a number greater or smaller than 20. If your policy statements overflow the tooltip box then increase this value, or if the box is too big, then you can decrease this value.
If you haven’t run Peek before, please read on as I explain how to create the required credentials and where to obtain the values for the other environment variables. You can skip the APEX steps, as APEX will not be used.
Continue reading “OCI User Access Review Made Easy”