
Throughout my development experience, I feel that I have had several major bursts-of-learning, due to problems which have made me re-evaluate how I approach architecting and developing a solution. I feel these ultimately make me better as a programmer, or at the very least, more versatile. I am sure some of these bouts of learning and understanding are near universal, experienced by most developers, such as understanding parallelisation, but others are somewhat more specialised, such as when I first started writing games, where having to take 60+ snapshots of a continuously evolving environment every second completely changed how I thought about performance and accuracy. Developing Cloud-Native applications (and indeed micro-service based applications, which share very similar principles) feels as though it is one of these moments in my development experience, and I feel it might be interesting to reflect upon that learning process.
I see the problem statement for Cloud-Native applications as something akin to: ‘you have no idea how many instances of your application will be running, you have no idea where they will be in relation to one another and you have no idea which one will be hit for any particular call’. That is a lot of unknowns to account for in your code, and forces you to think very carefully about how you architect and develop your applications.
At this point it is probably worth introducing the development principles associated with the 12-Factor App, which is held as something of a checklist for developing applications in a Cloud Native manner. While I feel that many of those principles are not associated with cloud-native development explicitly (such as the use of version control, build-servers, etc. which apply to all sorts of application development), I will refer back to them (typically if you see something like ‘Process’ or ‘Config’ in quotes, I am referring one of the 12 factors), and the problem statement above emerges from the directives to run applications as a number of concurrent processes, which can be scaled out and in as required.
Some Background
A lot of this learning has been acquired from different projects, demos and proof of concept development efforts, but there is also a unifying project to which I will continually refer. I have built and maintain a handful of additional security services for Oracle’s Identity Cloud Service, which implement the flow outlined here. This blog will use the development of that service in Node.js as a narrative device, as I have, over time incorporated learnings with regard to my approach and design into that service, even if the original development or discovery occurred on another piece of work.
The important traits of this service, with regards to understanding the evolution to cloud-native and to which we will continually refer are the following:
- It needs to maintain short/medium lived state, in order to hold a set of outstanding requests for authorisation
- It has operations which wait (via long-polling) for a change in state which is triggered elsewhere.
Starting Simple and Straightforward
My initial build of these services was as a proof-of-concept, or to use a term that I have come to loathe, a minimum-viable-product. It was designed to simply be functional, and no real considerations were made for scalability. At the time, here is how those key points were solved:
- Maintaining State: Single in-memory hash-map, lost when the process was terminated.
- Long-poll resolution: Internally the long-poll endpoint just polls the above in-memory map of requests every second until another service updated them.
So, the basic application architecture looked like this:

As you can probably see from this, in this case, the ‘native’ in cloud-native is a little bit of a misnomer, as it completely fails to satisfy the requirements for Concurrency mandated by 12-factor development. Rather, this is an application that emigrated to the cloud, and the focus will be upon the approaches which needed to be adopted to enable this to transform from functioning as an isolated process into scalable multi-instance application.
Shifting to Stateless
My initial build of these services had a pretty critical issue preventing it from scaling out with additional instances, and that was that the application was maintaining its own state locally, which meant that in order to resolve a created authorisation request, and resolve the long-poll associated with it is almost impossible, as each request would need the incredible fortune of hitting the same application instance. Possible with two instances perhaps, but certainly far too unreliable for any real purpose, especially given the implication in the problem statement: ‘you have no idea how many instances of your application will be running’.
This was a failure of the ‘Process’ factor, which mandates process statelessness. The approach that I took in order to satisfy this requirement was to push all of the state out of the application layer, and into a stateful data layer. The result of shifting all state out of the application services layer means that each instance is able to operate independent from one another, with any number of new instances able to be spun up anywhere, provided they have the same view of the underlying data layer. It is also an approach to providing multi-tenancy, as multiple tenants can use the same set of stateless services, and be routed to tenant specific data services.
In order to achieve this for my security services, I pushed my short-lived but stateful authorisation requests to a distributed cache, provided by Application Container Cloud Service. Had the state been less volatile (the Auth requests only live for 5 minutes), I could have pushed it down to a database, and then used data replication techniques to provide concurrency at that layer. In order to implement this, I wrote a caching library for node.js which extracts away all of the complexity of how caches are implemented in ACCS. The library is available here. You can read more about ACCS caching here, but the short version is that it creates a cache configuration URL in the container environment variables, thus satisfying both of the ‘Config’ and ‘Backing Services’ factors.
This yields an architecture which looks like this:

It is clear from this diagram that although the problem of a shared state is solved, I still have the same approach for resolving the long-poll endpoint. If anything, the problem is exacerbated, as rather than simply polling a local object, it is now polling a network resource. This is especially chatty given this polling happens once per second per open request.
Self-configuration and Discovery
Reducing network chattiness isn’t one of the twelve factors, but the process of resolving it raises a lot of questions about how to handle ‘Concurrency’ and application-wide ‘Configuration’. In this case, to reduce chattiness requires some sort of ability to communicate a state change across application instances, rather than waiting for the polling service to detect the change in the underlying data. This runs right up against the ‘you have no idea how many instances of your application will be running and you have no idea where they will be in relation to one another’ problem outlined in the beginning, or the ‘treat applications as independent concurrent processes’ mandate of 12 factor development. In order to tackle this problem, I set out to determine a mechanism by which applications could use some form of self-configuration in order to facilitate cross-instance communication.
The approach I decided to take was to use of a form of EDA (event-driven-architecture), which provides a pattern to allow updates to be distributed through a system and interested parties can subscribe to these updates. The complication lay in determining a method by which events could be distributed to all of the other application instances, to which the answer was ‘use the network layer’.
The cleanest approach to leveraging the network layer for event distribution while continuing the paradigm of ‘application instances don’t know and indeed shouldn’t know about each other’ is to utilise multi-cast groups. Multi-cast allows for the broadcasting of packets to all members of that group, and if we can configure application instances to join the appropriate group at start-up, the desired behaviour can be achieved. This requires some level of self-configuration, and introspection of the instance in which the application is running, in order to ensure the applications bind with appropriate network interfaces and all connect to the same network group.
Something akin to this:
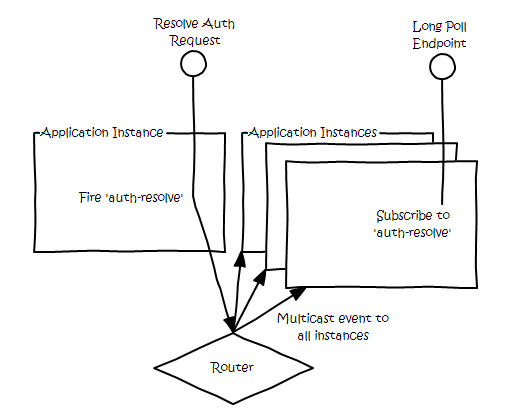
An approach I took was to inspect the available network interfaces to ensure all of the applications are joining the same network zone. I also determine a network group based upon a common value shared by all instances of that application. While this could be simply set as an environment or application specific variable, I was endeavouring to write a reusable library, which would configure itself appropriately for any application it was included in, preventing application ‘fusing’ (having multiple applications join the same event network, and receive events sent by the other application).
In order to achieve this self-configuration, I took a numerical hash of the application name, and then determined the multi-cast group and port based upon the modulo of this hash and the acceptable IP range/port numbers, as per this snippet of code:
//Hash in the range of 0-UINT_MAX var appHash = hashName(APPLICATION_NAME); var multicastGroup = ‘228.186.2.’ (appHash % 255); //Random port in IANA Ephemeral port range (49152 to 65535) var multicastPort = 49152 + (appHash % 16383);
This gives a little over 4 million multicast groups, which is likely enough to avoid collisions in most scenarios, but there is still room to expand this to more bytes of the multi-cast group IP address if required, or concatenate the Application name with its version number or some environment name (DEV, TEST, PROD, etc) if more separation is required and applications share network zones.
While multi-cast would be the cleanest method by which to perform application wide eventing, unfortunately I had to fall back on a different approach for my application to achieve the same thing. Instead of having each application join a multi-cast group, I had each application maintain a view of the other instances, achieved by inspecting the network domain name server (DNS), and send direct messages on cluster change. This approach leverages specific behaviours of the Application Container Cloud Service, so I will not go into it in depth. If you do wish to achieve something like this on ACCS, you can use my library, rather than have to go through the same discovery of the intricacies of the ACCS networking model. By implementing this, I was then able to fire events about my state change, to which long polling endpoints were subscribed (which was scenario of the sample application I packaged with the module, available on github here).
For applications which can’t even rely upon network level behaviours (because the instances could be geographically distributed or similar), then looking into a dedicated detached messaging system likely makes sense, but that is beyond the scope of what I considered.
Designing Applications to Fail
‘Disposability’ is one of the most interesting factors of the twelve factor app, as it mandates designing applications with the mindset that failure is inevitable, whether that failure is due to system issues or just the result of destroying running instances as you scale in.
In the case of this application, this means that I cannot treat the eventing structure as a reliable way to resolve my long polling calls since I may have lost the instance which is subscribed to the event, and left the client hanging. As this is providing a long-poll endpoint, I can rely upon predictable client behaviour in order to handle this scenario, as the very nature of a long poll implies that client is not necessarily expecting the server to respond before they timeout, and therefore will attempt to reconnect, at which point they will connect to a running instance. At this point, they should be able to check if the condition has been resolved, rather than resubscribe to listen for a state change that has already occurred, and will not be fired again.
In order to achieve this, I stored the information about the state-change in the cache, with a time-to-live equal to the long poll timeout, and when a new request is made to the long-poll endpoint, it first checks the cache before subscribing to the state-change event. As a result, should an instance listening for an event fail or be destroyed, when the client reconnects after the expected timeout, they are able to retrieve the change from the cache and respond instantly. As such, from a client perspective, the consequence of a node failure is a delay of the remainder of their long-poll period in the resolution of their request, in my implementation, 120 seconds at the most. This is not perfectly disposable, but it is minimally disruptive.
Overall I have found the process of writing applications with the mindset of ‘cloud-native’ enlightening with regards to how I architect my own applications. Simply designing applications to be resilient to node failure presents its own architectural problems, not to mention throwing the requirement for mechanisms to configure themselves to support concurrency and a need for stateless operation into the mix. Fortunately each of the solutions to the problems independently helped suggest approaches for the other problems, which enabled one of the major bursts-of-learning that I have experienced few times previously as a developer. It is a fascinating challenge, teaching me to think far more about the overall architecture of an application early in the process. I doubt that I have successfully captured all of the trials and errors in this post, but I hope that it can at least provide you with some insight; or hint as to how to solve a nagging problem. Or, if you are using ACCS, you can just use my libraries, and get the trials and errors all bundled up in code form…
