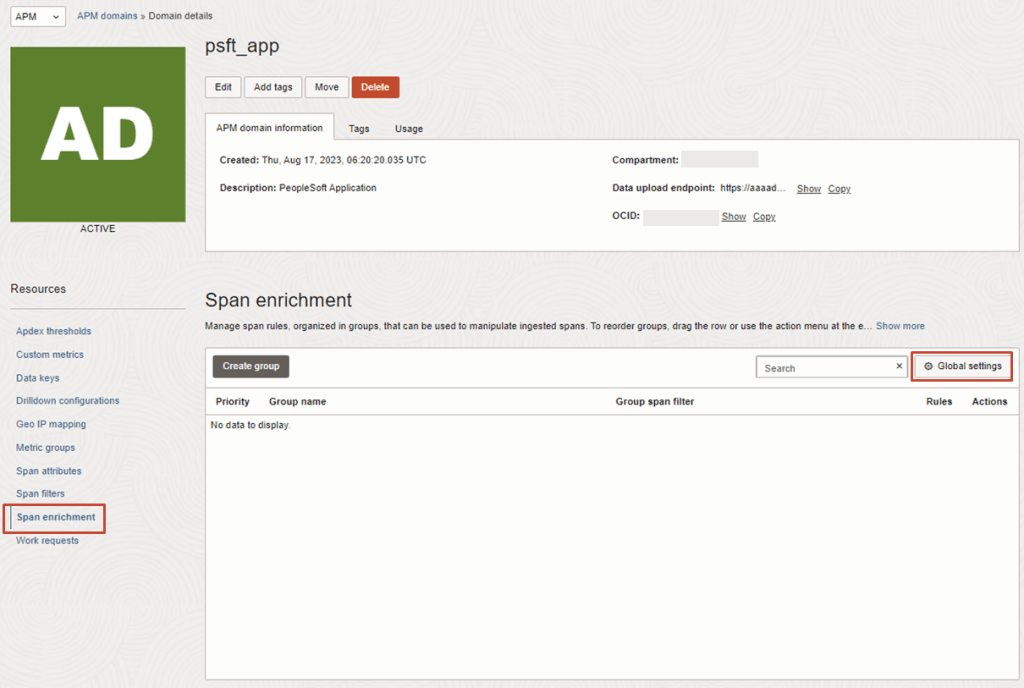
The Oracle Cloud Application Performance Monitoring (APM) service collects end user trace sessions for Real User Monitoring (RUM). By default the client IP is not captured for the end user session. For some customers, default Geolocation info (eg. Country, Region, City) may be sufficient for end user monitoring. However, for those who want to collect Client IP information as well, to enable this setting please see the following example.
Enable Client IP Collection for End User Session
For every End User Session, we want to capture the Client IP address location.
1. To do this, in the OCI Console, navigate to the OCI APM Service
OCI gives you flexibility to create custom metrics when no out of box metrics are available. There are two options on how this can be achieved. Depending on your use case let’s take a look at which choice works for you.
Requirements
OCI Monitoring Service
OCI Stack MonitoringService
View Metrics in Monitoring Service
Yes
Yes
Create Alarms
Yes
Yes – Automatically, emitted to Monitoring Service once Metric Extension is enabled for target resource
Metric Dimensions
Yes
Yes
Frequency Collection
Control by client API execution, cron job, scheduler or agent
Yes – can be configured when creating the metric extension.
Collection can be directly executed by OS command, Script(eg. Shell, Python), SQL, JMX or HTTP (REST API)
This is a guest IAM blog written by OCI Security expert Paul Toal.
Oracle Cloud Infrastructure (OCI) comes with its own, enterprise-class Identity and Access Management (IAM) service, which is used to manage users and their permissions within OCI. It can also be used for managing access to resources, applications, and services outside OCI, including on-premises. If you have been using OCI for some time, you may be familiar with Identity Cloud Service (IDCS) and how it was used to layer additional IAM capabilities over the core OCI IAM service. The capabilities from IDCS have now been merged into OCI through the introduction of OCI IAM Identity Domains, meaning IDCS no longer exists as a separate service. There is a great FAQ posted to answer many common questions about this change, including why Oracle has made the change and the benefits of this change.
Oracle has recently undergone the process of automatically migrating all existing OCI customer tenancies from IDCS to identity domains. In this article, we will examine the implications of the migration and the best practices following a tenancy IAM migration.
Today, Oracle Process Automation with its Recipes helps organizations to reach process excellence faster. The recipes are business process solutions developed with OCI Process Automation (OPA) and available for you once you have provisioned OCI Process Automation service.
Recipes can be deployed as-is, or extended to meet requirements customer-specific.
In addition, to expediting time-to-value for new deployments, the available recipes can be used also as a sort of blueprints for organizations who want to start with new processes built on OPA.
So, just to position the recipes and when better to use them, we can try to post some questions.
Are you a Developer and looking for quickly deploying new business processes?
Are you a System Integrator needing to start from a pre-built asset so to be later customized meeting better your needs without reinventing the wheel?
Are you looking for some samples to be used for demo purposes to test capabilities and functionalities without starting from scratch?
All these questions can find in the OPA Recipes the right answer.
Now, OPA includes the following recipes … and much more will come soon.
Every single Recipe has its own documentation to drive the implementer.
I suggest to carefully look at the system requirements before using those ones; all those recipes are intended only for guidance.
In order to run those recipes, you must perform the following configuration tasks on your Oracle Identity Cloud Service (IDCS) instance in order to successfully run the recipe.
Assign IDCS application roles
Create the required users in IDCS
After you’ve configured the roles and other resources, you can activate and run the application and test the process and some capabilities like business searches, how to escalate tasks using the native workspace or the analytics graphical view to see if the process flow is altered by manual intervention.
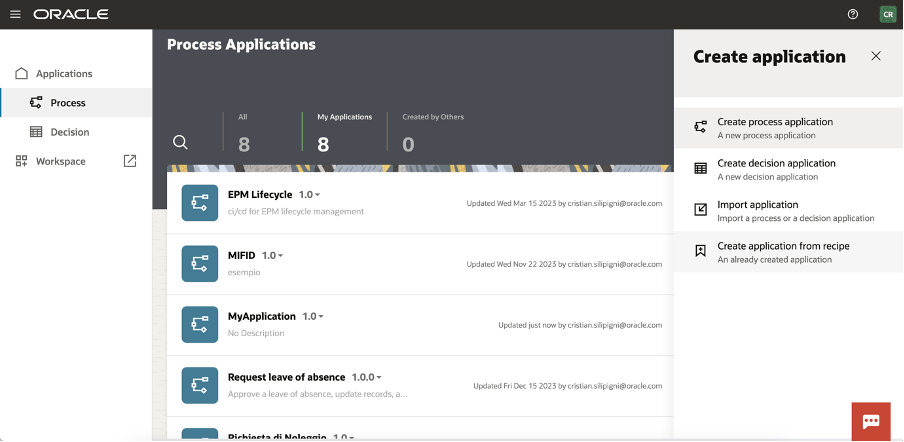
Now you can see how the “Credit Increase Request” can be imported into your own OPA instance:
Create a new process in the application process section
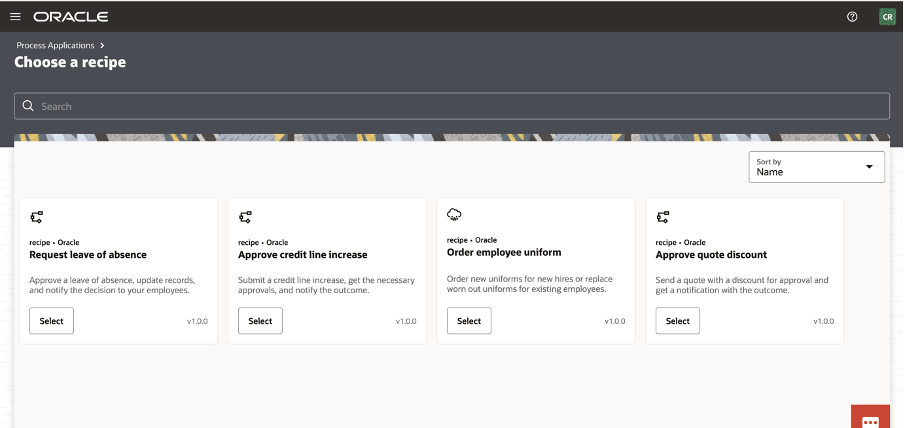
Click on the “Create Application from Recipe” action from the palette:
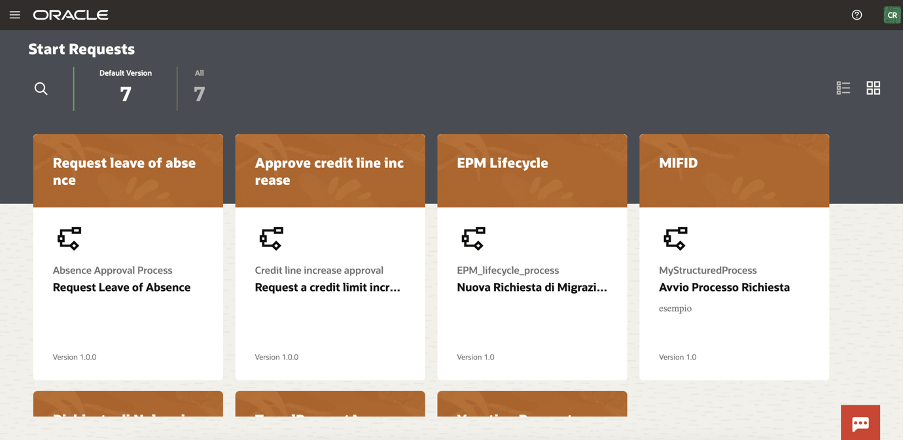
Select, for example, the Approve Credit Line increase
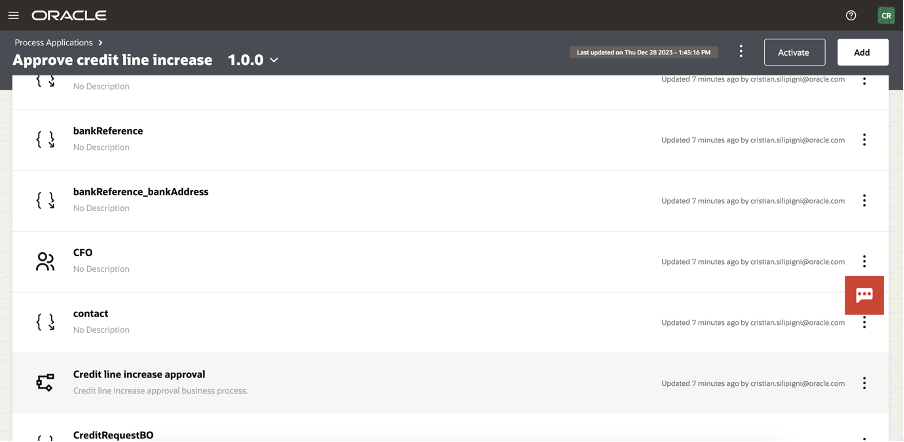
And now, you can see all the artifact imported in your application.
Selecting the “Credit Line Increase Approval” link, you can access the BPMN design of the process
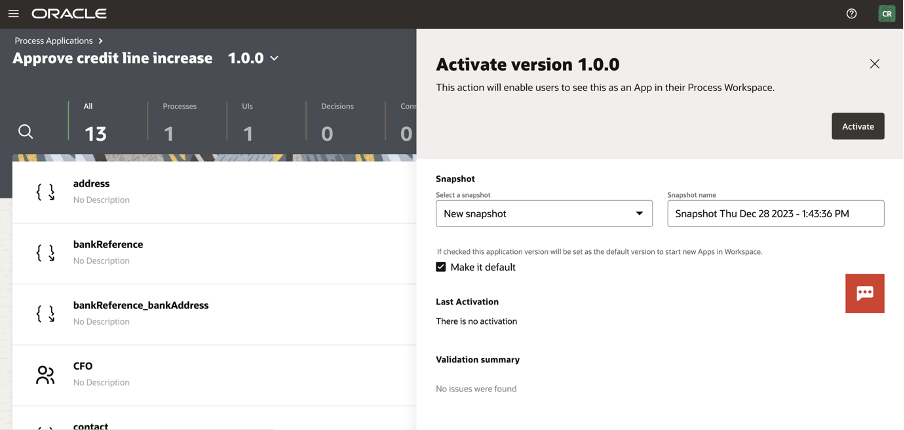
The process is now ready for you to be activated (or customized) selecting the “activate” button at the top of your page
And now ready to be tested in the workspace
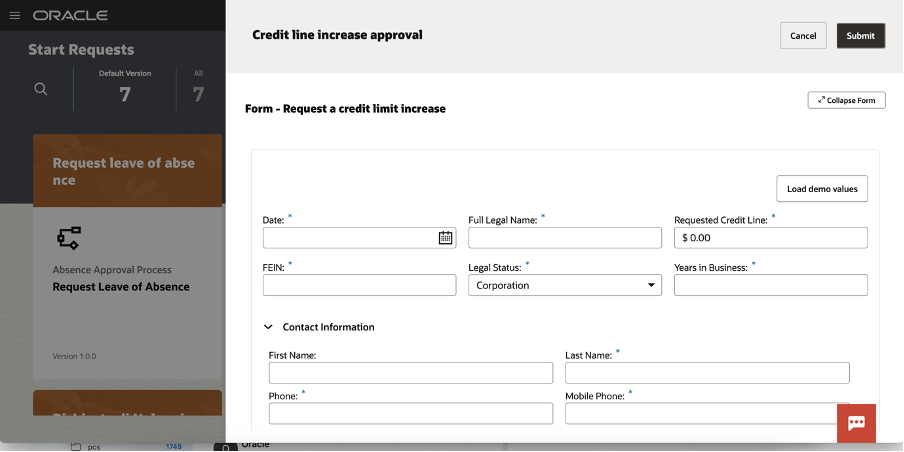
You can now start a new request and the web application will appear to you, something like that one here included:
You can load demo values to speed up the test so to quickly see the outcomes of the execution
A new item is now available to be worked by the assignee approving, rejecting, … all the actions that the human workflow will be configured for the specific user, group or application role
As we know, OPA can be used to support business processes to build “system 2 system” or “system 2 human” implementations and when the User Interface is required to interact with the running process you can also modify or extend the web UI leveraging the powerful features to adapt your web page, embedding basic and advanced controls so to drive the business user and simplifying his job reducing errors due to wrong data input
Try it by yourself… it’s a very good accelerator!!
One of the most interesting news of the current year is the capability introduced In OIC Gen3 few months ago. I’m talking about the chance we have today to manage events through Oracle Integration.
As we know, often projects require to decouple who can produce messages from who can consume those ones. This approach probably simplifies the integration approach making the applications independent from each other so that any change can be applied, for example, deleting/adding one or more subscribers, without impacting the implementation.
Of course, the decoupling can be built using external messaging queue solutions, something like OCI Streaming Service for which OIC can provide a native adapter or reusing what already used by the customer, for example a Kafka queue, quite common in real use cases.
The first approach probably enables the chance to provide an Oracle Cloud based solution built on top of OCI services delivering in this way an end2end solution based completely on OCI.
The second approach grants the customer to extend and innovate their own applications reusing what already in production adding with Oracle Cloud the most innovative technologies leveraging AI services, Autonomous Database, Oracle SaaS and much more.
At the same time, as explained at the beginning, it’s possible to manage such use cases directly from OIC itself without leveraging other components, or solutions. Everything is managed internally without extra effort in terms of resources or other software to be managed.
What required is to work with “Pub/Sub” pattern… something about the configuration of some actions from the OIC console.
So, to complete the case we need mainly to:
Create the Event type,
Create the Publisher,
Create the Subscriber
1.Create the event type
Starting from scratch we need to configure the event type.
OIC suggests a mockup as a payload just to provide you an example, but you can modify that one to adapt the format to your need in JSON format or eventually you can provide your own XML SCHEMA
2.Create the Publisher
Once defined the message type, it’s required to configure the publisher entity. To do it, you need to set up a new integration flow using one of the available patterns.
To define the Publisher, in my case I have created an integration flow with “Application” style, to include the Publish action from the palette which at runtime will push the message to the embedded event management system included in OIC. As you can see below:
After dragging the activity, you can see something like this:
In the “Publish” action it’s required to configure the Events type … exactly what we have defined during the step 1. In my case, the Event “NewAlarm” is what previously defined.
If you don’t have any Subscriber yet, when the publisher fires a new event, this one is retained for you in OIC keeping this one until when a new subscriber consumes that message as below shown:
3.Create the Subscriber
The last mile to be covered is about the subscriber. Now we can create a new integration flow for consuming Events as below shown:
Dragging this activity into your canvas, it’s possible to configure the Subscriber for the interested Event; in my case the “NewAlarm” event previously configured.
Now you are ready to run your sample just to see how it works.
Monitoring is fundamental to govern and check if everything works fine and above all as expected. Below some screenshots from the OIC console which shows the different levels of monitoring provided natively by the platform
It’s not a demanding activity; quickly you can do it by yourself… to understand how pub/sub pattern works on Oracle Integration
It’s very interesting feature what recently delivered with OCI Process Automation.
It’s possible now to upload in your workflow a document such a passport, driver license, … documents from where it’s possible to automatically extract data.
No more manual procedures but everything managed by the solution to automate business processes.
This is a meaningful improvement of the OCI offering highlighting synergies and native integration among the big number of OCI services available in each OCI region of the world.
Artificial Intelligence is today the most relevant technology from which we can take advantage in simplifying our lifestyle, reducing time with bureaucracy, and getting a benefit from other several new services before unimaginable.
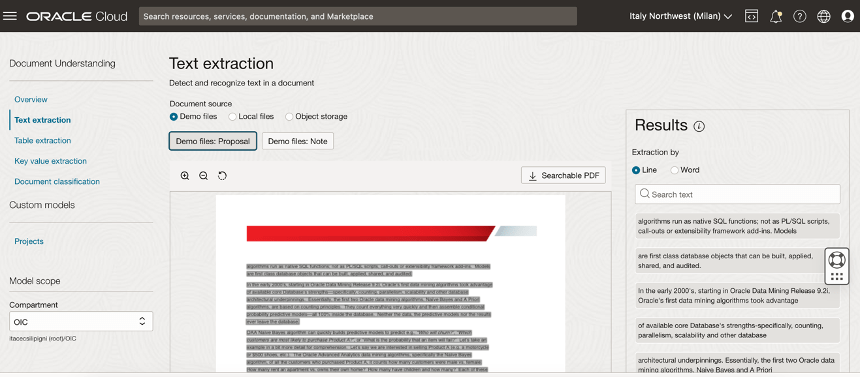
Oracle Cloud Infrastructure (OCI) Document Understanding, what natively integrated in Oracle Process Automation, is an Oracle AI service that enables developers to extract text, tables, and other key data from document files through APIs and command line interface tools. With OCI Document Understanding, you can automate tedious business processing tasks with prebuilt AI models and customize document extraction to fit your industry-specific needs.
You can easily identity this service navigating the OCI Console in the Analytics & AI section.
With this service, you can upload documents to detect and classify text and objects in them. You can process individual files or batches of documents using the ProcessorJob API endpoint.
The following pre-trained models are supported and offering support for different pre-trained model like:
Optical Character Recognition (OCR)
Text extraction
Key-value extraction
Table extraction
Document classification
Optical Character Recognition (OCR) PDF
In your daily life, how many times you need to show your passport, your driver license, or your health insurance card to start a new request?
Some examples are:
Renting a car
Accessing the hospital to do triage
Medical checkup in healthcare
Hotel check-in
…
This is the reason why today Oracle can offer this added value in his Cloud offering… to simplify your daily activity, to make your life better.
A simple process, as I said before, can be that one about the “Car Rental”. Trying to imagine a human workflow behind, we can think about a BPMN process used to manage every step where for example an approval is required.
We can also imagine, not necessarily a process behind but simply the need to upload some info or data which need to be sent to other applications or database so that OPA can be used to easily configure a webpage from where it’s possible to upload data into an Oracle Database using its REST adapter or leveraging the DB adapter included in Oracle Integration Cloud Enterprise Edition (which includes OCI Process Automation).
I have tried to imagine a “Car Rental” process designing a step by step process for example when a long term rental is requested and its acceptance needs to be approved
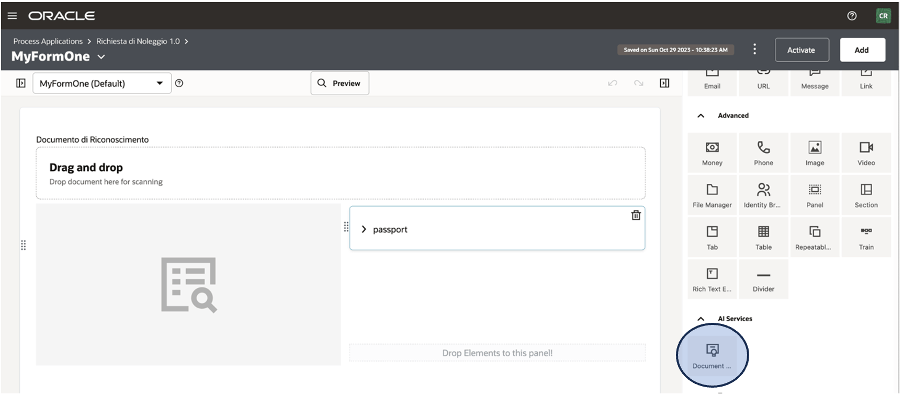
As you can see below, when you design your WebForm from OCI OPA Console you can find on the right side, included in the activities section, the new icon about the AI Document Understanding.
This icon can be dragged & dropped into your canvas to model the web UI as you prefer and need.
It’s a pre-built integration, so you don’t need to think about REST invocation or similar. Everything is pre-configured for you and then you can easily use it without coding or similar stuff.
Once the process is implemented (here a quick overview how to do it), you can enable this one for production purposes
The operator can use the web UI to start a new request, clicking on the pre-defined process and/or including the new application in a web portal or into the Oracle SaaS springboard in according to the specific process.
Once the operator has identified the right process, clicking on the “Nuova Richiesta di Noleggio”, the webform appears to accept the required info.
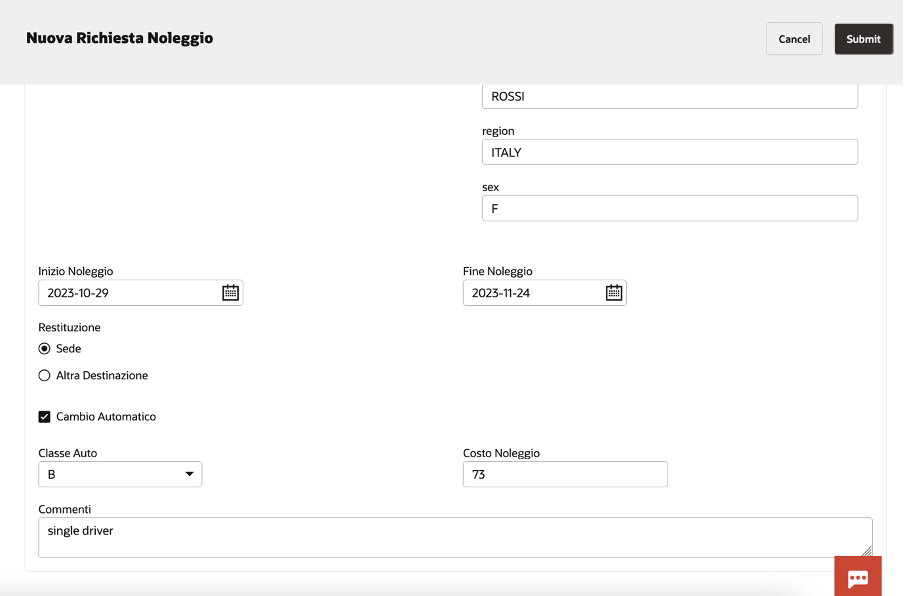
If, AI Document understanding, has been properly configured, the end user can upload the image of the passport, or other provided documentation, so to start the automatic data acquisition
In a while, you can see how automatically all personal data appear on the right side of the page, filling the right field.
You can, of course, add other info to enrich the information required … something like below included. The web UI is highly customizable, and you can build your own web page as the business requires.
In this way, the desk operator can scan your documents and with a simple click, uploading the image, it’s possible to collect all the required information without huge effort taking advantage of:
Less time for data entry
Less errors for manual activities (i.e. reading passport and typing them)
Better and quicker customer experience
I encourage you to test it by yourself to personally understand how much it’s easy to do it. A very low effort to improve processes introducing in your business innovation, efficiency, and automation.
It’s been a while since I sat down and wrote anything. #JoelKallmanDay and the #APEX community was worth finding a spare moment and focus on.
The current action (that is in development) for some of our experiences that are share #DrivenByData #PlayWithSeriousIntent that you might have seen at a few different events. I’ve explored the space of introducing QR codes into the experience. There are a few different ways that we are looking at it.
The newest certification from Oracle Cloud Infrastructure is the OCI 2024 Certified Networking Professional. It is still in beta mode and will be with this status until 15 October 2023; returning as a Generally Available certification early in December of this year. If you are interested in taking this certification, visit the Oracle University learning path for it.
Oracle Cloud Infrastructure 2024 Certified Networking Professional certification is for Cloud professionals that have at least two years of general experience with OCI, or other IaaS cloud providers and are already familiar with general Networking concepts. An Oracle Cloud Infrastructure 2024 Certified Networking Professional has demonstrated the hands-on experience and knowledge required to plan, design, implement, and operate networking solutions on OCI. The abilities validated by this certification include:
• Plan and Design OCI Networking and Connectivity Solutions
• Design for Hybrid and Multicloud Networking Architectures
• Implement, and Operate Secure OCI Networking and Connectivity Solutions
• Migrate workloads to OCI
• Troubleshoot OCI Networking and Connectivity issues.
The below public documentation will give you step by step instructions what needs to be done to protect OIC from malicious and unwanted internet traffic with OCI WAF (Oracle Cloud Infrastructure Web Application Firewall).
A while back I witnessed a Terraform presentation where a subnet’s IPv4 CIDR block was constructed from a parent VCN by invoking a Hashicorp function called cidrsubnet. This function is very useful because it can save time when you have multiple VCNs in your Terraform code. And it is universal, it can be used when there are several concurrent Terraform providers in the same code.
The function’s format is like this: cidrsubnet(prefix, newbits, netnum).
The prefix field is for the VCN CIDR. You can enter a variable in the prefix field. For example cidrsubnet(var.vcn_cidr, 8,1). Let’s say that the VCN CIDR is 10.0.0.0/16, then the value of var.vcn_cidr is 10.0.0.0/16. So, the function looks like this: cidersubnet(“10.0.0.0/16”,8,1).
The newbits value is the number of digits that you will be adding to the actual CIDR value. 16 + 8 = 24, so the subnet will be a /24 subnet.
The netnum value is for completing the actual subnet, and it depicts the “raw” decimal number of the binary portion of the subnet side of the CIDR, in this case is the third octet. The result for the subnet is 10.0.1.0/24.
This example illustrates it better:
cidrsubnet(“10.1.2.0/24”, 4, 15). 24+4 = 28, so the subnet will be a x.x.x.x/28 subnet.
The value in the netnum field will help us identify which of the 16 possible /28 subnets we’re creating. On a /28 subnet, in the fourth octet, the four left bits are the subnetwork bits. Convert 15 (the netnum value) to binary and you will get 1111. Place it on the subnetwork side of the fourth octet and you will get 1111|0000. The decimal value of the whole octet is 240, therefore the subnet is 10.1.2.240/28.