This is my fifth #DaysOfArm article that tracks some of the experiences that I’ve had so far. And just to recap from the first post (here) on June 12 2021.
It’s been just over 2 weeks since the launch of Ampere Arm deployed in Oracle Cloud Infrastructure (OCI). Check this article out to learn more (here). And it’s been about one week since I started looking into the new architecture and deployment, since I started provisioning the VM.Standard.A1.Flex Compute Shape on OCI and since I started migrating a specific application that has many different variations to it to test it all out.
This is my fourth #DaysOfArm article that tracks some of the experiences that I’ve had so far. And just to recap from the first post (here) on June 12 2021.
It’s been just over 2 weeks since the launch of Ampere Arm deployed in Oracle Cloud Infrastructure (OCI). Check this article out to learn more (here). And it’s been about one week since I started looking into the new architecture and deployment, since I started provisioning the VM.Standard.A1.Flex Compute Shape on OCI and since I started migrating a specific application that has many different variations to it to test it all out.
There’s been numerous announcements about Oracle Cloud Infrastructure (OCI) adding Arm-based Compute to the list of Virtual Machine (VM) Shapes. Check some of the announcements (here) and (here).
You can also watch it (here) too with Clay Magouyrk, Executive Vice President, Oracle Cloud Infrastructure. Note: The link above has more content and videos.
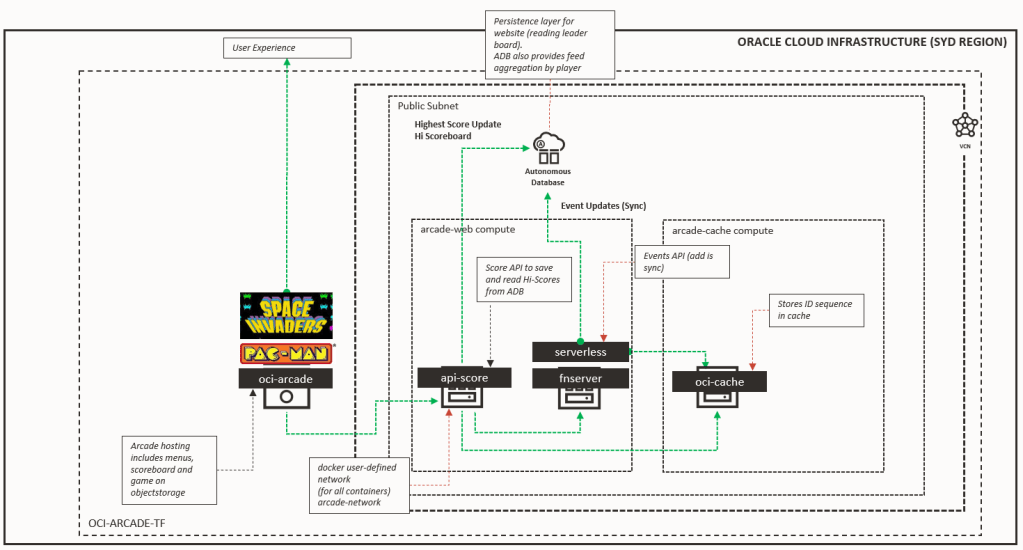
Have you seen the OCI Arcade? We have built the architecture deployable on OCI Always Free Tier.
Recently in the OCI Always Free Tier, an additional services has been added to include 4 cores and 24 GB of RAM of Ampere A1 Compute. With this additional capacity, it made sense for OCI Arcade to be ported to this A1 Compute Shape. Here is what we did and why.
I’ll keep this short … I recently came across an update to one of the Oracle Cloud Infrastructure Quick Starts for WordPress. The specific addition that caught my eye was a micro deployment of WordPress – 1 x VM and 2 x Docker images (check out the repo here). I looked at that and thought:
This Terraform package would be good for Always Free Tier
Which it was, downloading the repository and created an Oracle Resource Manager Stack (learn more here) and applied the stack. And within minutes, I had a working instance of WordPress.
Yes – it is a single instance. Yes – I could have built something that was more secured. Yes – I could have built something that was more scalable – using MySQL Database Service or Oracle Kubernetes Engine.
But putting this altogether, I spent less than 10 mins on this and I can get going. And it is Always Free. The nice this is that I know that this model can expand as it requires (and only when I need to).
I thought about this for the upcoming hackathon too #WorldInnovationDay (https://hackmakers.com) where people are wanting a site to display their solutions. This is a way of doing it and keep it as part of their portfolio.
If you need an environment to try this out – head to the following link and sign-up. https://www.oracle.com/au/cloud/free/. If you are part of the hackathon, we are giving participants a promotion with $500USD credits into a new tenancy and no credit card. Try this out for yourself.
Here’s the architecture of the OCI Arcade extended with Coherence-CE
I was talking to Tim Middleton who works in the Coherence Development team the other day about different scenarios that we can work on some areas that demonstrate the scale out – two scenarios were obvious (to me) – Apache Spark was one and the other was Coherence – an In-Memory Data Grid.
And with that I built out the OCI Arcade to bring Coherence-CE (Community Edition) into the mix. There’s some lots of cool stuff that you can do with Coherence-CE and the bulk of the content is (here).
To get access to the OCI Arcade with Coherence – you can find these on a git branch in the repositories.
The simple use-case that we used Coherence-CE for was a simple identity key for the instance id (ie each game plays has a unique identifier). The nice thing was that it was all in Javascript. This following fragment was the only thing that I needed to do to integrate Coherence-CE into the app itself.
const opts = new Options()
opts.address = 'oci-cache:1408'
app.get('/id', (req, res) => {
var game_id = req.query.game_id;
var session = new Session(opts)
var map = session.getMap('oci-id')
setImmediate(async () => {
console.log('Map size is ' + (await map.size))
if ((await map.has(game_id)) == false) {
await map.set(game_id, { id : 1 })
res.send('{ "id" : 1 }');
} else {
res.send('{ "id" : '+(await map.invoke(game_id,Processors.increment('id',1)))+' }')
}
await session.close()
})
});
From the Coherence-CE cluster perspective – there’s docker images from docker hub already (here) that I could use for it. So replacing what I did previously with Kafka in the deployment architecture and putting Coherence-CE in its place was simple. (NB: There were some changes in terms of stopping events being fired to Kafka and also creating the instance id from this method instead of a Date.now() method. Simple things).
There’s plenty of different directions that we can go from here – session-based cache scenarios, high-availability scenarios, in-memory data processing scenarios. There are plenty to extend and learn from.
If you want to try this out yourselves, you can get an Always Free Tier environment – head to the following link and sign-up. https://www.oracle.com/au/cloud/free/.
After building out the OCI Arcade on Oracle Always Free Tier (check out a recent blog here), I was on a roll. What was next? The inspiration came after a virtual session with some other mentors that I was working with. The need to share code, have an environment that was easy to use as well as provide a method of multiples users developing in the same workspace.
I remembered back in 2016, that I used Cloud9 which was a development environment that I could plug into with a full Java environment. We used to for our Developer Experience workshop for some client-side dev (with the client-side installation issues). Cloud9 which since got bought by AWS. And then a few years ago, Eclipse Che and Codenvy surfaced as a potential alternative. It’s still around and going strong from what I see. And I dug a little deeper into Che and found that Che’s browser-based development environment is based upon a project called Theia – a Cloud and Desktop IDE. … So bingo … here it is Theia-IDE deployed into Oracle Always Free Tier for cloud-based / browser development environment. Check out more about what we did.
(Update – 3 December 2021 – There’s been some changes to the docker hub images that were originally used. They are no longer available and hence this is currently broken if you try it. I’ve been investigating the use of the Theia-Blueprint repository to build the cloud environment which seems to be going ok. More to come).
I’ve started posting articles related to the project that @stantanev and a few of us are working on. This is snapshot of the puzzle that is to build out a APIs on the Oracle Always Free Tier.
As a demonstration of capability, we built a few different APIs using fnproject (https://fnproject.io/) – an open-source container-native serverless platform. As part of Oracle Cloud Infrastructure, there’s Oracle Functions which is the managed Function-as-a-Service based upon this same project.
Let’s take a look at it here and see what it took to get going. Also, this is being deployed into VM.Standard.E2.1.Micro compute shapes (which is 1 OCPU and 1GB of memory) and hence there are some considerations to make sure we get the most out of the kit we have access to (for free).
In a previous blog, I explained how to provision a Kubernetes cluster locally on your laptop (either as a single node with minikube or a multi-node using VirtualBox), as well as remotely in the Oracle Public Cloud IaaS. In this blog, I am going to show you how to get started with Oracle Container Engine for Kubernetes (OKE). OKE is a fully-managed, scalable, and highly available service that you can use to deploy your containerized applications to the cloud on Kubernetes.
I am thrilled with the Oracle’s Gen2 Cloud Infrastructure architecture, where Oracle completely separates the Cloud Control Computers from the User Code, so that no threats can enter from outside the cloud and no threats can spread from within tenants.
Obviously with more security, there comes more coordination, especially at the moment of invoking OCI resources APIs. Luckily, Oracle did a good job at providing a simple to use CLI and SDK (see here for more information).
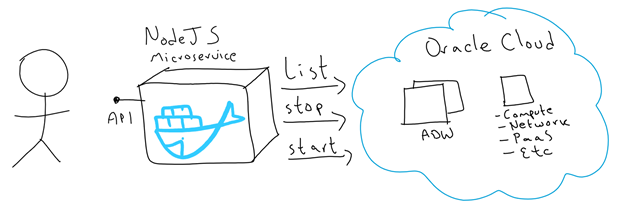
For the purpose of this blog, I built a simple NodeJS application that helps demystify the security aspect of invoking OCI APIs. Check this link for examples of running similar code across other Programming Languages.
My NodeJS application manages OCI resources in order to:
List ADW instances
Stop an ADW instance
Start an ADW instance
I started this NodeJS application to list, start and stop ADW resources. However, I designed this application to easily extend it to invoke any other type of OCI resources.
I containerised this application with Docker, to make it easier to ship and run.
A few days ago, we published an article that shows how to provision and connect to Oracle Autonomous Transaction Processing Database (ATP). Based on this, we got multiple requests to also demonstrate how to extend the connection to the Autonomous DB, not only from SQL Developer, but also from polyglot microservices.
In this blog, we are going to take a step forward and create a simple “Hello World” NodeJS application that exposes some REST APIs that push and pull data using an Oracle Autonomous DB. The idea is to give you all knowledge required, to be start building your own microservices, consuming data from Autonomous DB.